[152] Gadający woltomierz cz. 1
Prawdziwą przyjemnością podczas zabaw z Arduino jest wyciskanie z tego komputerka tak zwanych siódmych potów, a dzisiejszy projekt do takich będzie należeć. Tak, Arduino jest komputerem i to ośmiobitowym – jeśli mowa o Uno R3 i pochodnych. Co oznacza, że w roku 2026 patrzy się na niego z pogardą. Tymczasem dla tych, którzy lubią panować nad układami mikroprocesorowymi w pełni bez patrzenia nań jak na czarną skrzynkę, to właśnie ośmiobitowce są wdzięcznym poligonem do zabaw, ponieważ ich złożoność nie przekracza możliwości poznawczych ludzkiego mózgu, niekoniecznie mózgu geniusza.
Dzisiaj postaram się wycisnąć co nieco z tego przestarzałego, a jednak wciąż użytecznego serca Arduino. Zbudujemy mówiący woltomierz, ale – uwaga – bez dodawania do Arduino czegokolwiek z wyjątkiem głośnika. Innymi słowy, całe źródło gadania wraz z kodem musi się zmieścić w pamięci pokładowej, której mamy 32 kB. Z punktu widzenia audio – żałośnie mało. Czy aby na pewno?
Zacznijmy od założeń. Niech nasze Arduino informuje o mierzonym napięciu za pomocą dźwięków – konkretnie serii wyrazów od zera do dziewięciu. To nieco ułomne, bo w przypadku na przykład 235 woltów usłyszymy: dwa, trzy, pięć. Ułomne, ale użyteczne. Taki woltomierz jest w miarę czytelny, a ma jedną, ogromną zaletę: uwalnia wzrok od cyferek czy wskazówki, pozwalając na pomiary w układzie bez wstępnego podłączania kabli. Ale tym się zajmiemy później. Na razie przeanalizujmy sprawy audio.
Nagrajmy sobie odliczanie: od zera do dziewięciu. Proponuję raczej liczyć żwawo, dynamicznie, bez wyróżniania jakiejkolwiek cyfry. Mój przykład można usłyszeć w załączniku pierwszym. Teraz trzeba owo nagranie przygotować do stawianych zadań. Do tego celu będę używał aplikacji Adobe Audition, ale wskazówki tu przedstawione są uniwersalne i niezależne od edytora.
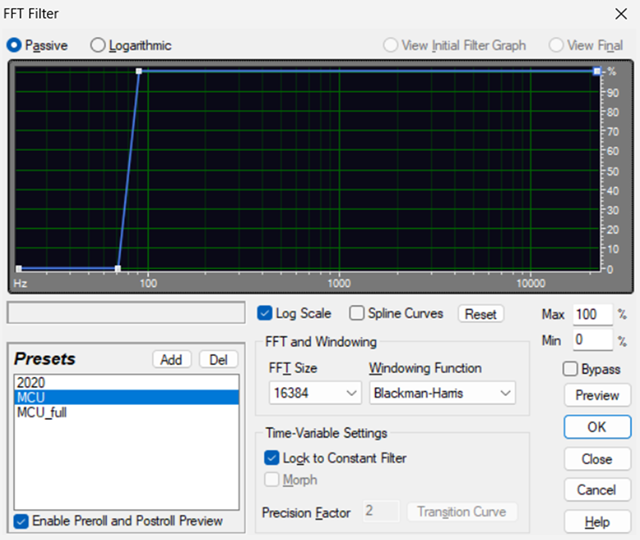
Najpierw więc wytnijmy najniższe basy: nic nie wnoszą, a zabierają energię przekazowi.
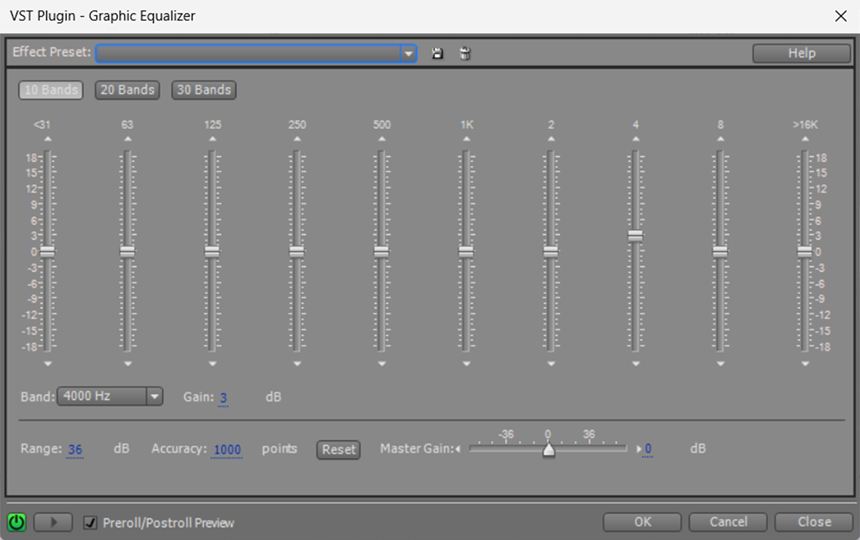
Proponuję także podbić okolice 3-4 kHz, tak o 3 dB, nie więcej. Zwiększy nam to czytelność komunikatów.
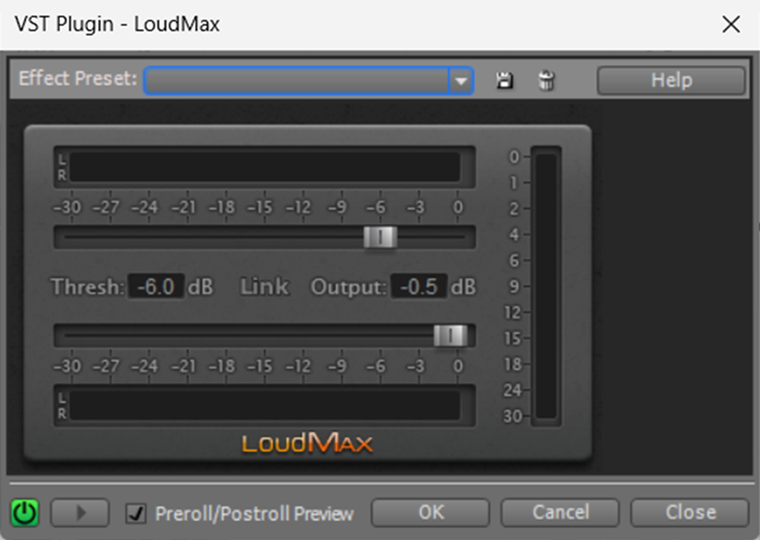
Kolejnym elementem będzie użycie kompresora, który wyrówna głośności zarówno poszczególnych wyrazów jak i ich fragmentów.
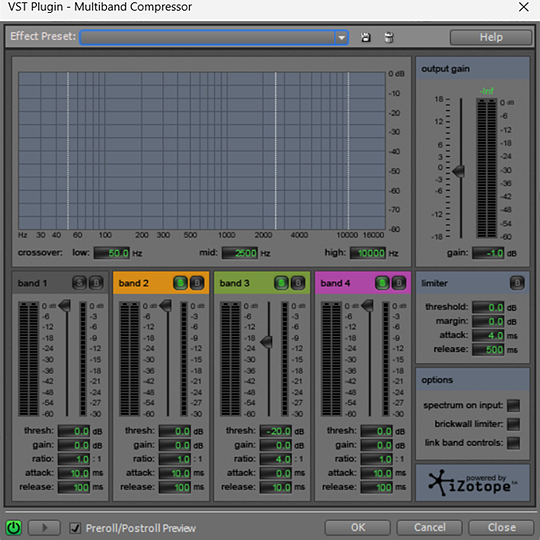
Ostatni efekt to użycie deesera, czyli kompresora głosek syczących. On znowu przywróci równowagę między różnymi rodzajami odgłosów.
Czeka nas teraz mozolna praca: należy wyciąć wszystkie przerwy i marudzenia, scalając ze sobą wypowiedziane wyrazy – zupełnie nierozdzielone. Taki plik brzmi to dziwnie, ale docelowo nie będziemy używać całego nagrania, a fragmentów. Dlatego podczas tej operacji trzeba pozaznaczać granice między cyframi. Potem potniemy ten słowotok na kawałki. Zauważmy, że wszystkie dziesięć cyfr po tej operacji udało się zawrzeć w trzech i trzech dziesiątych sekundy. Ile to jest bajtów? Przyjmijmy: zapis mono, 44,1 kHz przy 16 bitach zajmie nam 2,34 MB. Arduino, które dysponuje 32 kB, zupełnie się do odtwarzania takich sampli nie nadaje. I tu powinniśmy historię zakończyć, sięgając po przynajmniej jakiegoś ARM-a albo kartę pamięci. Tymczasem należy się zastanowić, czy da się obniżyć jakość tak, by zmieścić ponad dwa megabajty danych w 32 kB.
Mowa ludzka jest w pełni czytelna po ograniczeniu pasma do 4 kHz, a nawet niżej. Wszak pierwszy program polskiego radia nadający na falach długich nie przekracza kilku kiloherców pasma. Więc mamy pierwszy potencjał. Drugi tkwi w rozdzielczości. Dla tak dynamicznych i krótkich komunikatów słownych obniżenie jej do ośmiu bitów będzie praktycznie niesłyszalne. Zatem – do roboty.
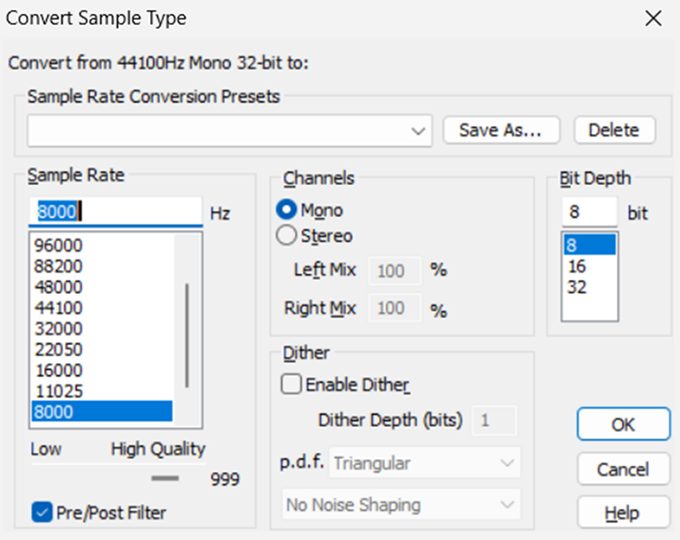
A teraz posłuchajmy wyniku, którego możemy posłuchać w załączniku drugim. Dźwięk jak gdyby zmatowiał, ale nadal jest czytelny. Najważniejsze jest jednak to, że teraz zajmuje – uwaga: 26 kB. A to nam się spokojnie zmieści w pamięci pokładowej Arduino Uno.
Trzeba teraz opracować sposób na to, by ten plik wepchnąć do Arduino i jakoś go wygenerować. Na temat generacji dźwięków przez Arduino napisałem kilka artykułów, jednak zawsze korzystaliśmy z kart pamięci. Dziś nie będziemy potrzebować niczego. Jak zwykle skorzystam z płytki edukacyjnej TME, gdzie mogę podpinać różne rzeczy, w szczególności głośnik. Zbudujemy przedstawiany już przeze mnie kiedyś prymitywny przetwornik cyfrowo analogowy z użyciem PWM.

Po szczegóły zapraszam do wspomnianego artykułu, tutaj tylko przypomnę: jeśli częstotliwość pracy PWM będzie wystarczająco duża i będziemy zmieniać wypełnienie zgodnie z danymi z pliku audio, w głośniku pojawi się dźwięk bliski temu, co nagraliśmy. Tak więc mamy do rozwiązania następujące problemy: przenieść plik z dźwiękiem do szkicu i napisać program, który te dane wyśle na głośnik. Przypomnę, że głośnik musi mieć przynajmniej setkę omów, a jeśli użyjemy bardziej zwyczajnego – należy podłączyć go przez rezystor.
Do pierwszego etapu będą potrzebne następujące działania. Najpierw zapiszemy nasz ośmiobitowy dźwięk o częstotliwości próbkowania osiem kiloherców nie jako typowy WAV, a plik bez nagłówka, tak zwany surowy RAW w formacie „bez znaku”.
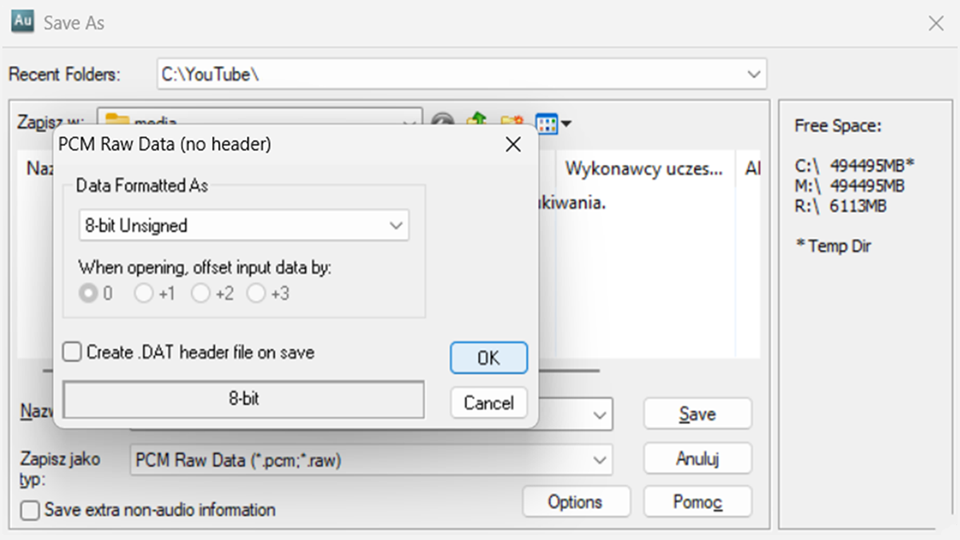
Będzie to znaczyło, że wartości przyjmą liczby naturalne od zera do 255, przy poziomie ciszy na pozycji 128. Innymi słowy, wykres przesunie się o połowę zakresu, by uniknąć liczb ujemnych. Powstanie bliźniaczy plik z rozszerzeniem PCM, ale troszkę mniejszy, bo nie będzie zawierać żadnych danych poza samym dźwiękiem.
Teraz musimy sobie zrobić z tego tablicę przyjazną dla języka C, którą wkleimy potem do szkicu. W sieci znalazłem malutki program: bin2hex, który zamienia pliki binarne na tekstowe tablice. Program nie ma interfejsu, ale składnia jest prosta. W wyniku jego działania dostaniemy wielką tablicę.
Czas na drugi etap. Program będzie dość prosty, choć wybiegnie poza typowe arduinowe elementy, bo wprost będziemy operować na rejestrach kontrolera, przystosowując je dla naszego odtwarzacza.
#include <avr/pgmspace.h> // Zapisy co prawda nie są wymagane, ale zalecane.
#include <avr/interrupt.h>
const unsigned char sample[] PROGMEM = { // Tablica zawierająca próbki sampla.
0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x81, 0x81, 0x81, 0x81,
0x81, 0x81, 0x80, 0x80, 0x81, 0x82, 0x81, 0x81, 0x80, 0x80, 0x81, 0x80,
0x80, 0x81, 0x81, 0x7F, 0x7F, 0x81, 0x81, 0x81, 0x80, 0x82, 0x83, 0x80,
// Dla czytelności usunąłem pozostałe wiersze tablicy.
0x80, 0x7F, 0x80, 0x81, 0x80, 0x80, 0x80, 0x80
};
const int sampleLen = sizeof(sample); // Długość sampla (dźwięku).
volatile int samplePos = 0; // Adres aktualnie odtwarzanej próbki sampla.
void setup() {
pinMode(9, OUTPUT); // Ustaw port PWM jako wyjściowy.
TCCR1A = 0b10000010; // Konfiguruj timer 1: nieodwracające PWM, szybkie PWM.
TCCR1B = 0b00011001; // Zliczaj do ICR1, praca bez prescalera (16 MHz)
ICR1 = 1999; // Ustaw częstotliwość przerwań na 8 kHz (16MHz/8kHz-1)
OCR1A = 128; // Startuj od wartości ciszy.
samplePos = 0; // Zeruj adres odtwarzanej próbki sampla.
TIMSK1 = 0b00000010; // Podłącz do przerwań źródło pochodzące z timera 1
sei(); // Włącz przerwania.
}
void loop() {
}
ISR(TIMER1_COMPA_vect) { // Obsługa przerwań od timera 1
if (samplePos < sampleLen) { // Jeśli wciąż trwa obsługa odtwarzania sampla...
OCR1A = pgm_read_byte(&sample[samplePos++]); // Ładuj próbkę z tablicy do rejestru PWM i zwiększ jej adres.
} else { // Jeśli to już była ostatnia próbka...
TIMSK1 = 0; // Wyłącz przerwania.
}
}Na początek – osadzamy dwie biblioteki: pgmspace.h oraz interrupt.h. W zasadzie tych wpisów może tu nie być, ale są zalecane, więc nie dyskutowałem z tym. Następnie znajdziemy tablicę, w którą należy wkleić to, co przed chwilą wygenerowaliśmy. Dla czytelności pozostawiłem tu tylko cztery wiersze, w oryginale jest ich ponad dwa tysiące. Kolejno definiujemy stałą zawierającą liczbę bajtów, które wykorzystuje nasz plik z dźwiękiem. Zamiast liczyć te bajty, zlecimy to zadanie kompilatorowi, używając instrukcji sizeof() Dzięki temu będziemy mogli łatwo podmieniać dźwięki, nie zawracając sobie głowy czasem ich trwania. Ostatnia zmienna samplePos to adres aktualnie odtwarzanej próbki, początkowo – zerowy.
W części wstępnej najpierw zadeklarujemy pin 9 jako port PWM. Architektura narzuca użycie tylko jednego z dwóch pinów: 9 albo 10. Następnie mamy serię wpisów do rejestrów związanych z timerem pierwszym, który będzie generował cykliczne przerwania używane do generacji dźwięku. Nie wchodząc w szczegóły, musimy ten licznik skonfigurować w ten sposób, by generował impulsy z częstotliwością 8 kHz, bo z taką zapisaliśmy nasz dźwięk. W końcu po ustawieniu poziomu na nasze umowne „zero” czyli ciszę – pamiętajmy o przesunięciu wykresu – można podłączyć przerwania do timera, a następnie włączyć je globalnie.
W głównej pętli nic się nie dzieje, odtwarzanie ma miejsce w przerwaniach. Muszą mieć one taką właśnie dziwną nazwę. Wewnątrz jednak nie ma większych tajemnic. Jeśli wciąż odtwarzamy dźwięk, tzn. nie doszliśmy jeszcze do końca, należy załadować kolejną próbkę z tablicy zgodnie z aktualnym jej adresem, po czym adres należy zwiększyć. Natomiast gdy dojdziemy do końca, należy odłączyć licznik od przerwań. Jak więc widać, program jednorazowo odtwarza zapisaną frazę, po czym pozostaje w pętli bez końca aż do kolejnego resetu. Samo w sobie nie ma to jeszcze sensu, ale pozwoli nam posłuchać wyników i w ogóle sprawdzić, czy niczego nie pomyliliśmy. W załączniku trzecim znajdziecie ten szkic z niewyciętą tablicą, a w kolejnym artykule uczynimy z tej procedury coś użytecznego, czyli „gadający woltomierz”.

Inne artykuły z tej kategorii

















































































 Jak wyświetlić cyfry o rozmiarze 10x8 i 10x16 pikseli?
Jak wyświetlić cyfry o rozmiarze 10x8 i 10x16 pikseli?

























